I want to use this page to document the entire journey of building a fully Automatic Internal Link Builder plugin for WordPress.
Signup for the Internal Link Builder Beta/Review Copy
Log Date: 8th Feb 2024
Why build another WordPress internal link making tool ?
I have bought LinkWhisper and Linksy and implemented on my websites.
They do simplify the internal link building process but they are not Automatic.
With LinkWhisper and Linksy, the website owner still has to login and check each post and then scan for matching links that can provide the inbound link.
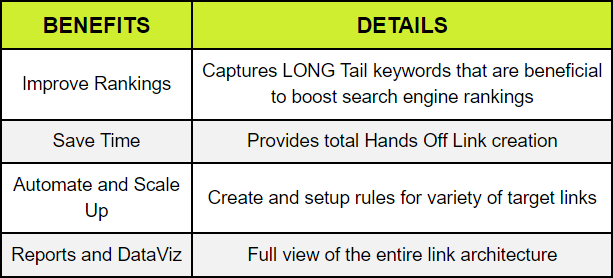
Here is my idea of completely automated approach to internal linking mechanism
Long Tail Contextual Link Building for WordPress
Basically, the process is a small Data Engineering Project
- You break the documents into sizable chunks
- Collect all data
- Process all data
- Run AI (artificial intelligence algorithms such as NLP)
- Score the text chunks
- Run Matching algorithm and generate suggestions
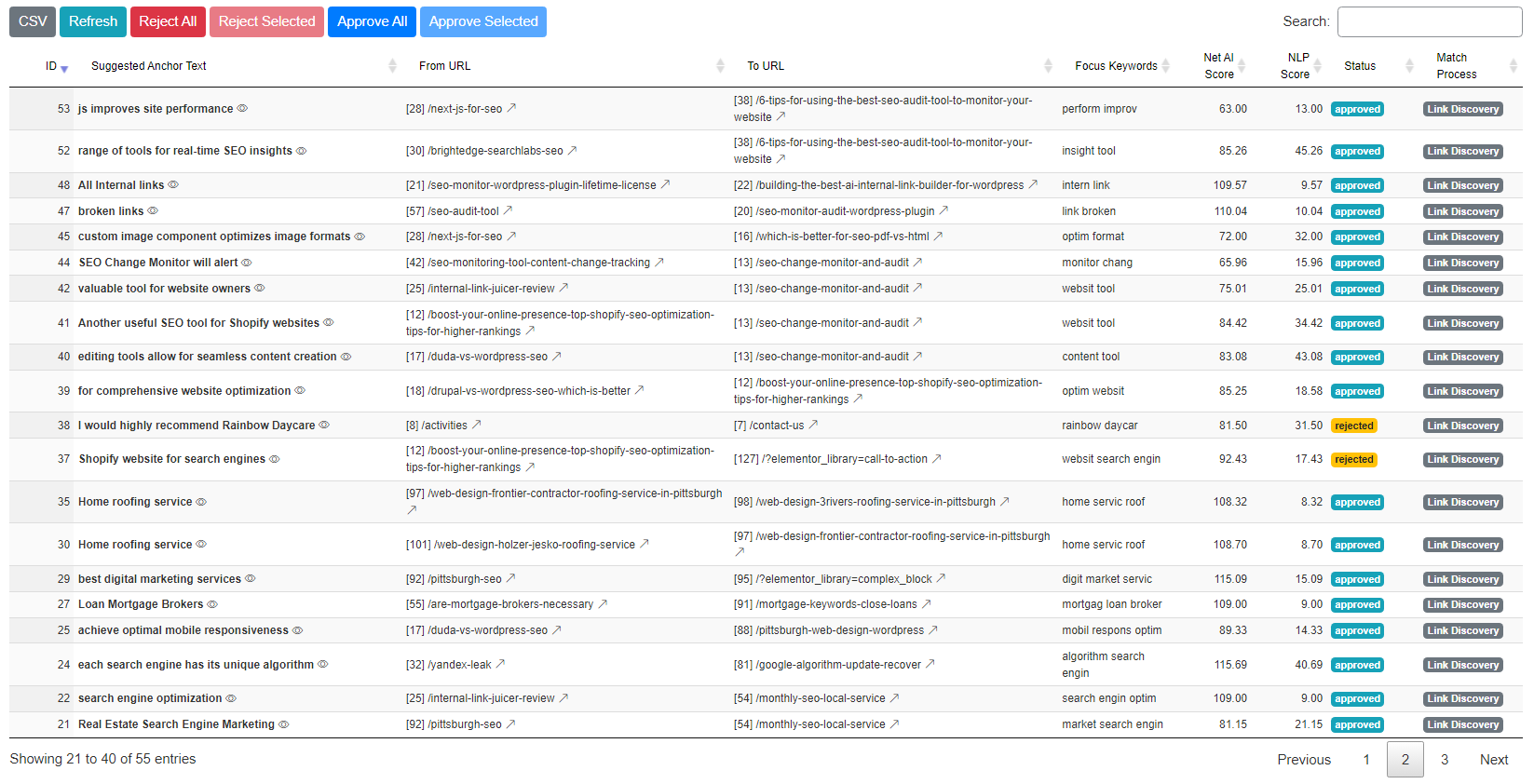
- At this point, we can take a complete Hands-off approach or include a manual intervention
- If you setup “Auto Approval” then the system will implement the internal link insertion and then send you a complete report for review.
- The manual review allows the website owner to review -> approve or reject each or all the suggestions.
- Once approved and all links are inserted, it will still present the WordPress user to UNDO anything that is out of place.
This all looked fine on paper.
I decided to leverage the existing framework of SEO Change Monitor plugin as it already had the link/URL interface.
Although this will change for the CrawlSpider Internal Linker plugin.
Where did we spend the majority of the time ?
- My approach to this was similar to any Data Analytics project. So most of the heavy lifting is done using the MySQL/ Mariadb database.
- Use PHP for just the interface and keep it to bare minimum
- I was surprised that majority of the time was spent in understanding how WordPress stores data, sanitization, escaping, UTF8 and how to safely package the content back into the WordPress wp_posts table.
- Another major chunk of time was spent in tweaking the algorithm to generate the best and juiciest long form anchor text.
Once the initial engine was completed, I started having fun!
It is super fun to see all the different keyphrases and anchor text getting collected in the database tables.
It is super fun to see the change in match behavior by making small tweaks to the matching algorithm.
The matching engine seems to be working very good. I need to tweak the chunk breaking algorithm a little bit.
Also, as I was testing on a cloned website with over 170 pages, that it was considering some low content pages as candidates for internal linking.
I want to test if the algorithm can detect such pages and not include them for consideration.
As I look into the data, there is so much potential and useful information can be derived out of it.
- Identify Broken Links
- Data Visualization for linking structure
- Keyword Cannibalization
- Keyword densities
- Generate N-Gram reports
Again, I want to keep the scope of the initial MVP very narrow. Not sure if all of the above can be incorporated on day one.
Here is a sneak peek on some data visualization tests. Not sure which one will make it
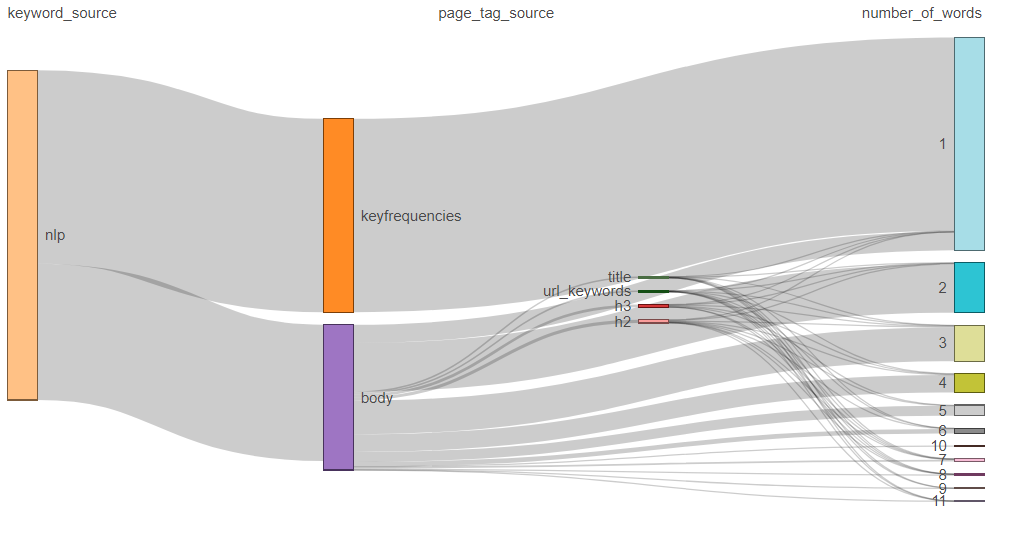
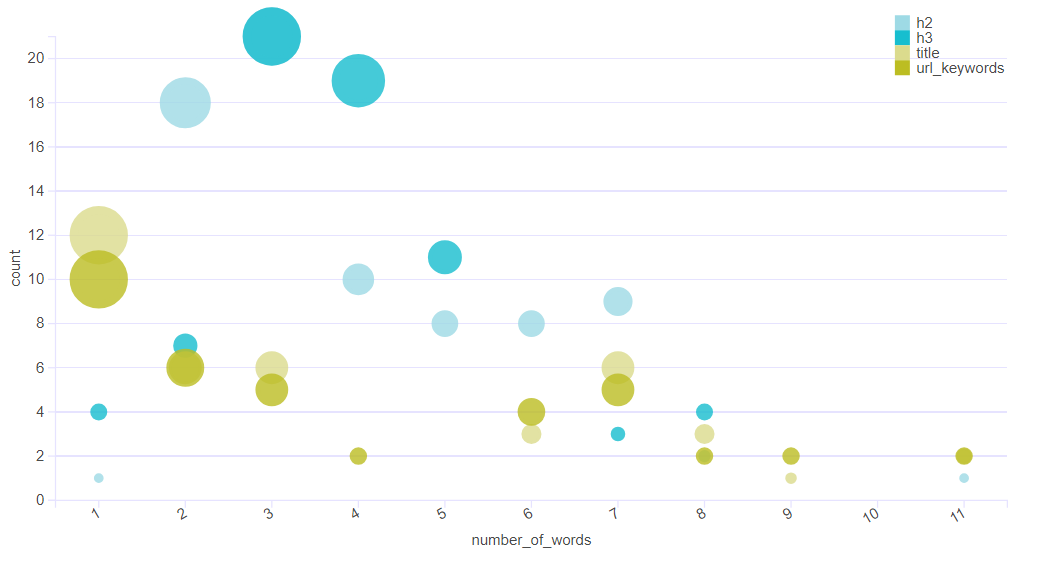
Log Date : 9th Feb 2024
Majority of the time was spent in detecting low content pages.
Many times the HTTP header will return the content length as -1
The URLs that server zip and images they seem to consistently have positive values.
For the WordPress posts, it is easy to gather this from the WP Posts table.
“You should also checkout” seems to be a bad habit of this writer 😉
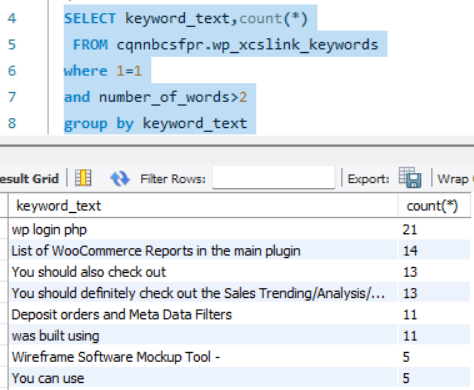
For now, any content less than 500 characters is a thin page does not deserve any link love.
Why should a thin page with less number of words deserve any internal links?
And because it has so less words, it cannot generate enough keyword juice to link out to other pages.
So far, thin pages are ruled out from linking out or incoming links.
Log Date: 2/22/2024
Duplicate Entries and Heartbeats
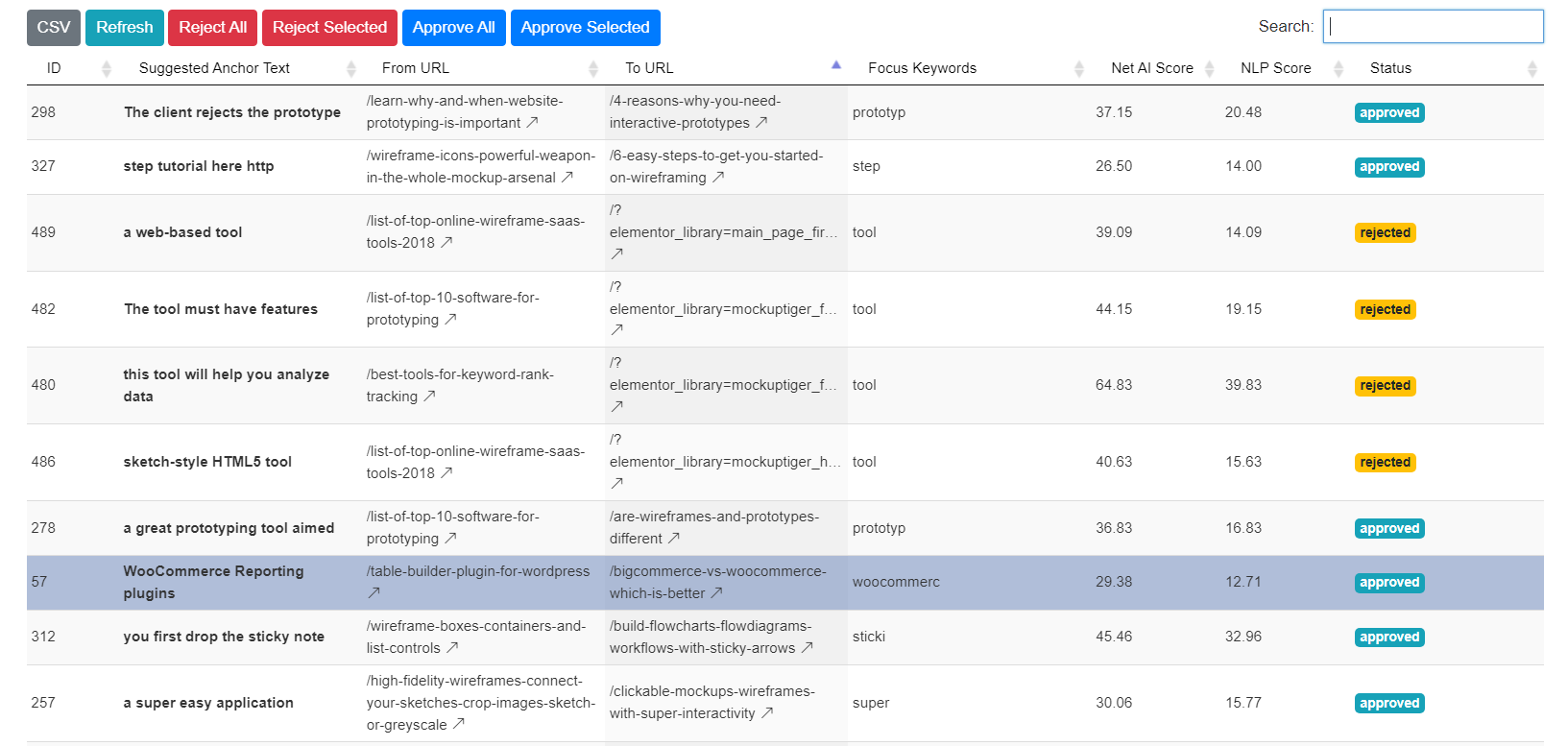
For the past few days, a very interesting test scenario emerged. As the crawler goes and starts collecting all the keyphrases and keywords from each page and then it triggers the matching algorithm.
During this keyword matching algorithm, the crawling process tries to determine the best anchor text between two pages, one is the from URL and the to URL.
I started seeing results like this
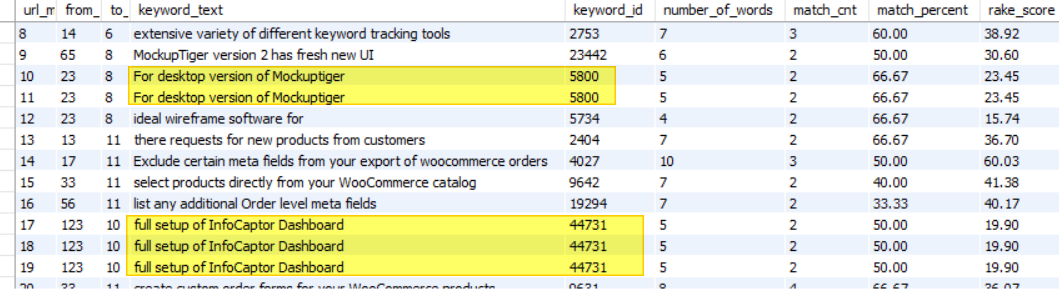
There is no way the crawl engine would find duplicates as shown above. The yellow highlighted rows indicate the same anchor text multiple times. The very fact that the keyword_id is also the same it suggests that it is the same keyword that is inserted into the match table.
How could this be happening?
I started thinking about the band-aid solution such as putting primary keys in the match table so that such duplicate records are never inserted but it kept bothering and the scenario needed further investigation.
After going through multiple rounds of code and logic verifications, I decided to turn on deeper logging of the matching algorithm.
Immediately after looking at the generated logs, all bulbs turned on!
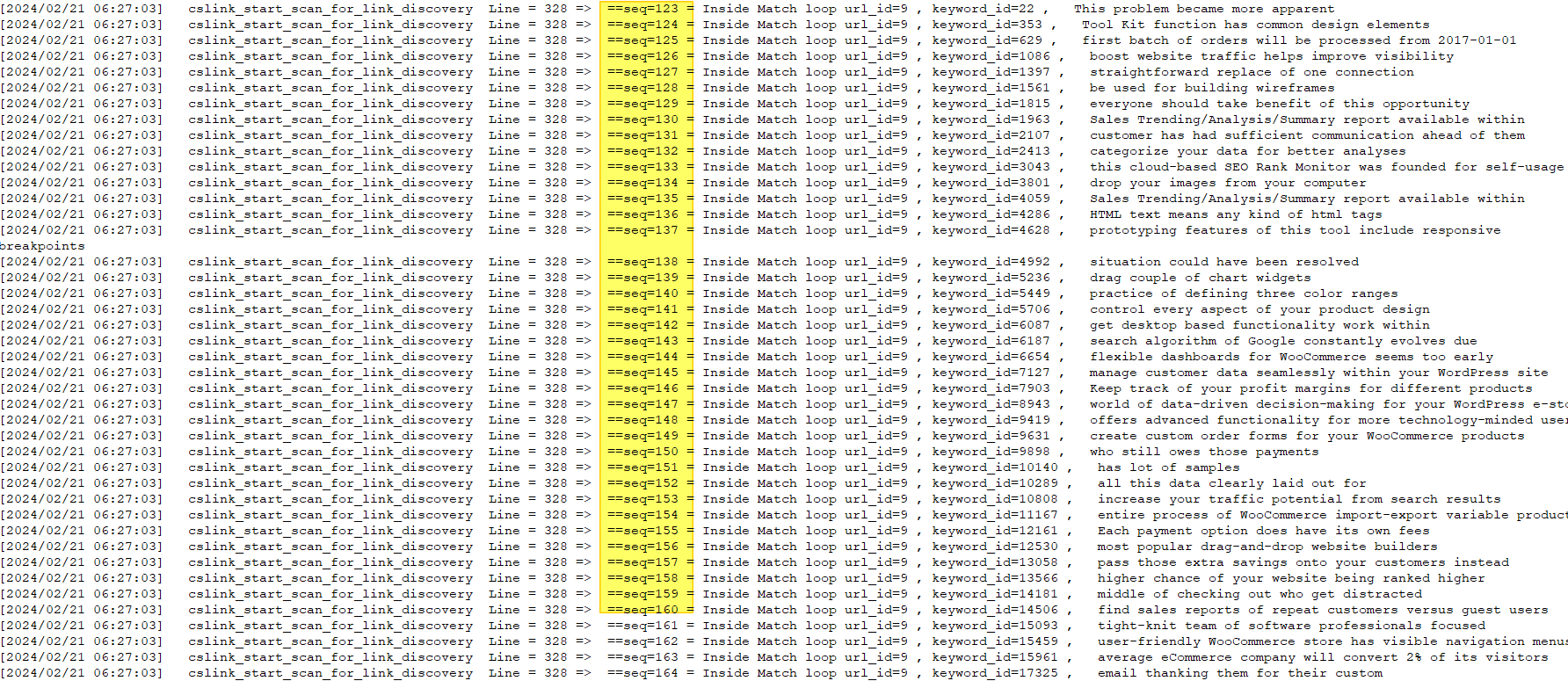
This never happened on the windows environment. The duplicate match entries seemed to be an occurrence on the linux hosting environment.
Look at the log output from Windows. The sequence numbers are perfectly linear as expected. Each crawl matching algorithm execution will sequentially go through the keywords and determine if it matches and determine the match scores.
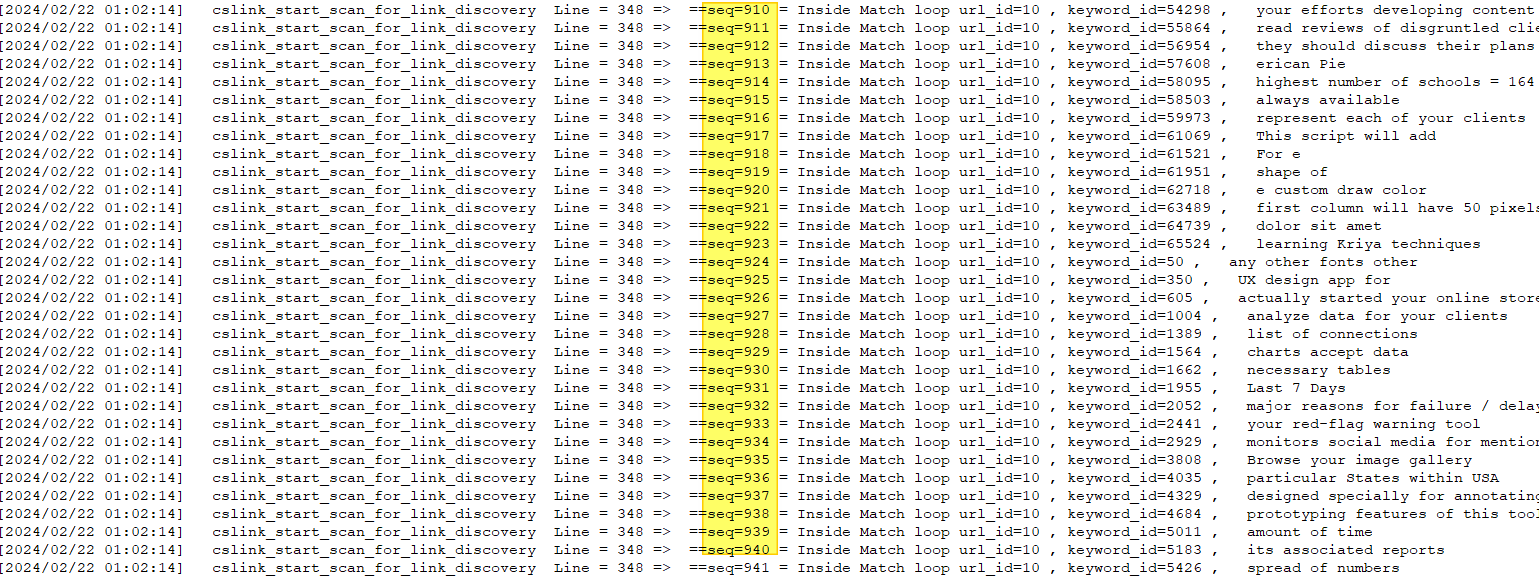
Now look at the log from the linux execution
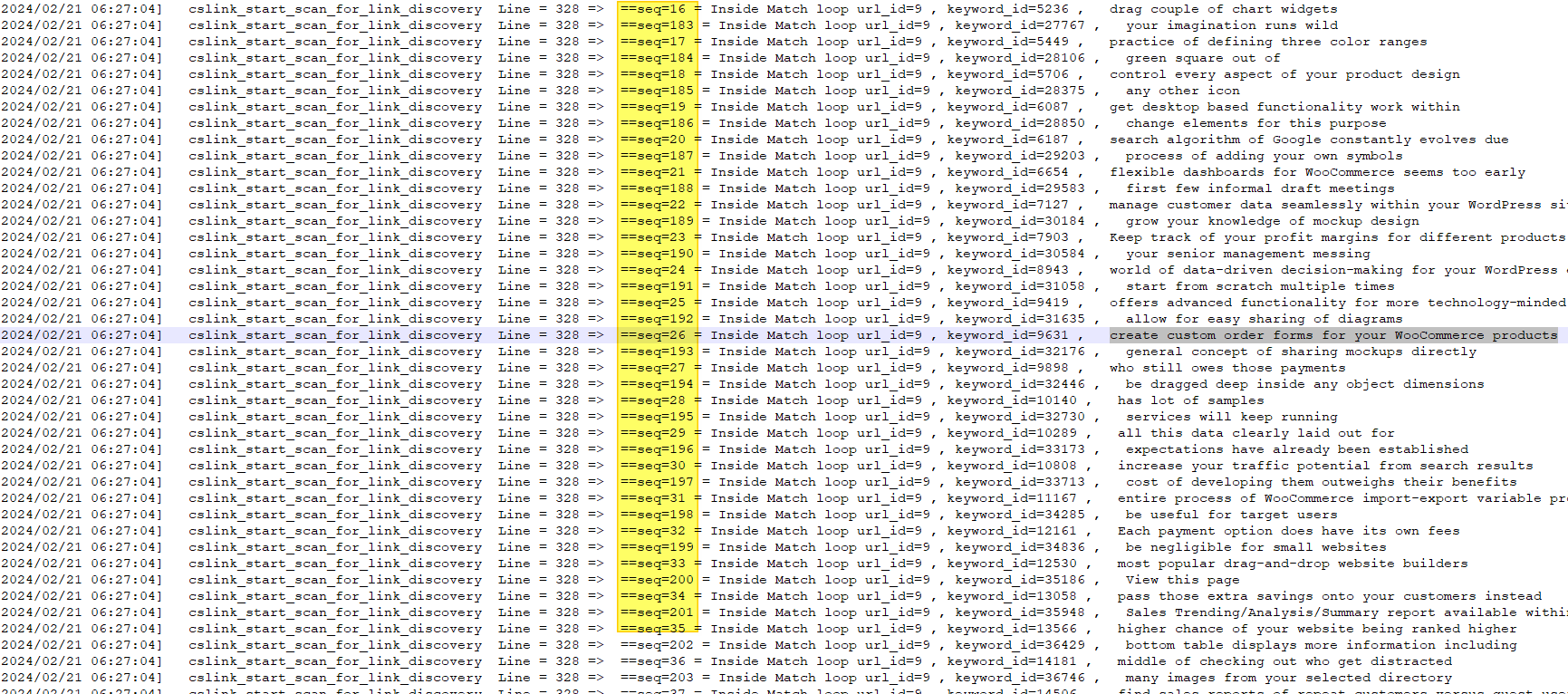
As seen, the sequence numbers are linear initially but then in the second screenshot, they are not. It seemed like two separate sequence streams are being recorded. This is when everything clicked!
Here is the summary and resolution
- In Windows environment, PHP process terminates as soon as the client terminates or when the set_time_limit expires. So basically every 30 seconds the PHP process will die.
- The link builder crawler is designed to be resilient and pick up from the same spot where it died or terminated during the previous execution.
- On Linux enviornment, the PHP process does not terminate and continues in the background.
- The UI detects that there is a server timeout
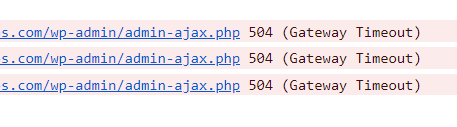
- Noticing the Gateway Timeout, the UI triggers another crawler instance
- This explains the two separate trains of sequence numbers.
- The original crawler run is still continuing in the background with no way to stop except to kill it.
- The second crawler run is trigger after say 30 seconds
- This being a WordPress plugin and keeping things simple, there was no need to implement any kind of message queue.
Having known the exact cause of the duplicate entries was a great relief! But now the solution to this problem was challenging. Considered various solutions and approaches such as message queues, locking rows using mysql select for update but everything seemed overkill for a plugin.
The problem at hand could be avoided if there was only one process running all the time. How about ensuring only a single instance of the crawl engine is running at any given time.
To solve, a very simple approach is being implemented namely “HeartBeat”. A running process will continuously update and tickle the heartbeat. Everytime a new process that gets triggered will check when was the last heartbeat. Using this knowledge the triggering process will go into a hold pattern until it determines that heartbeat has died. Will update soon how this testing goes!
Data Visualization Experiments
Here are few samples
Treemap to display content size
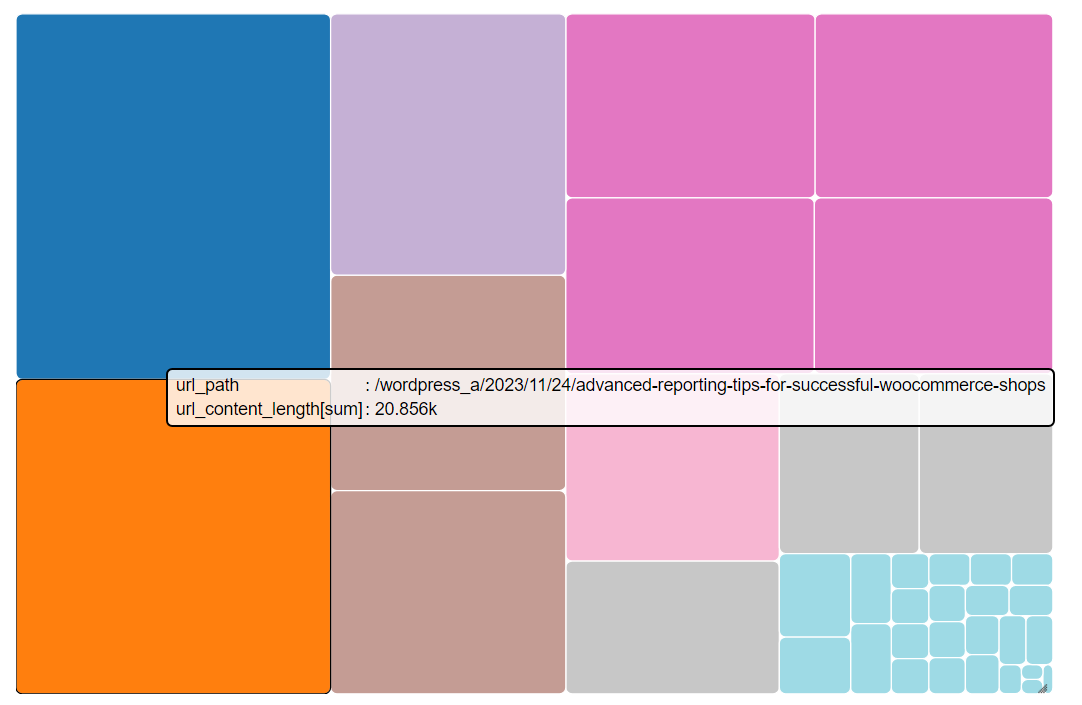
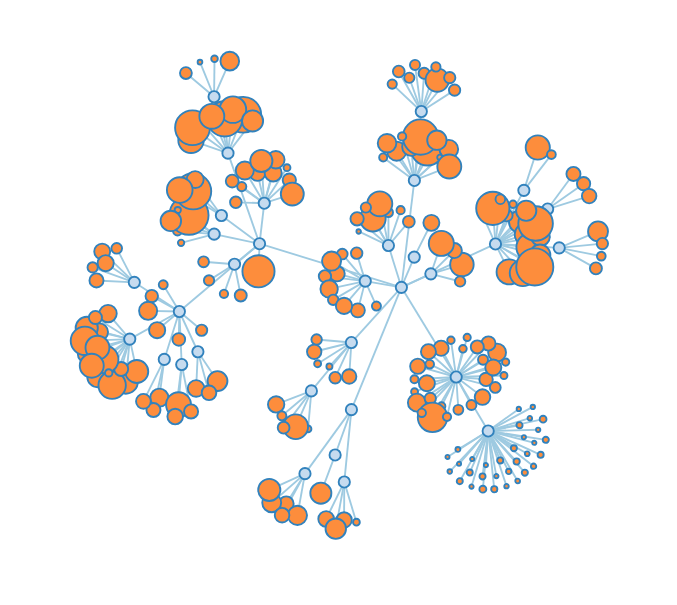
Radial Crawl Map
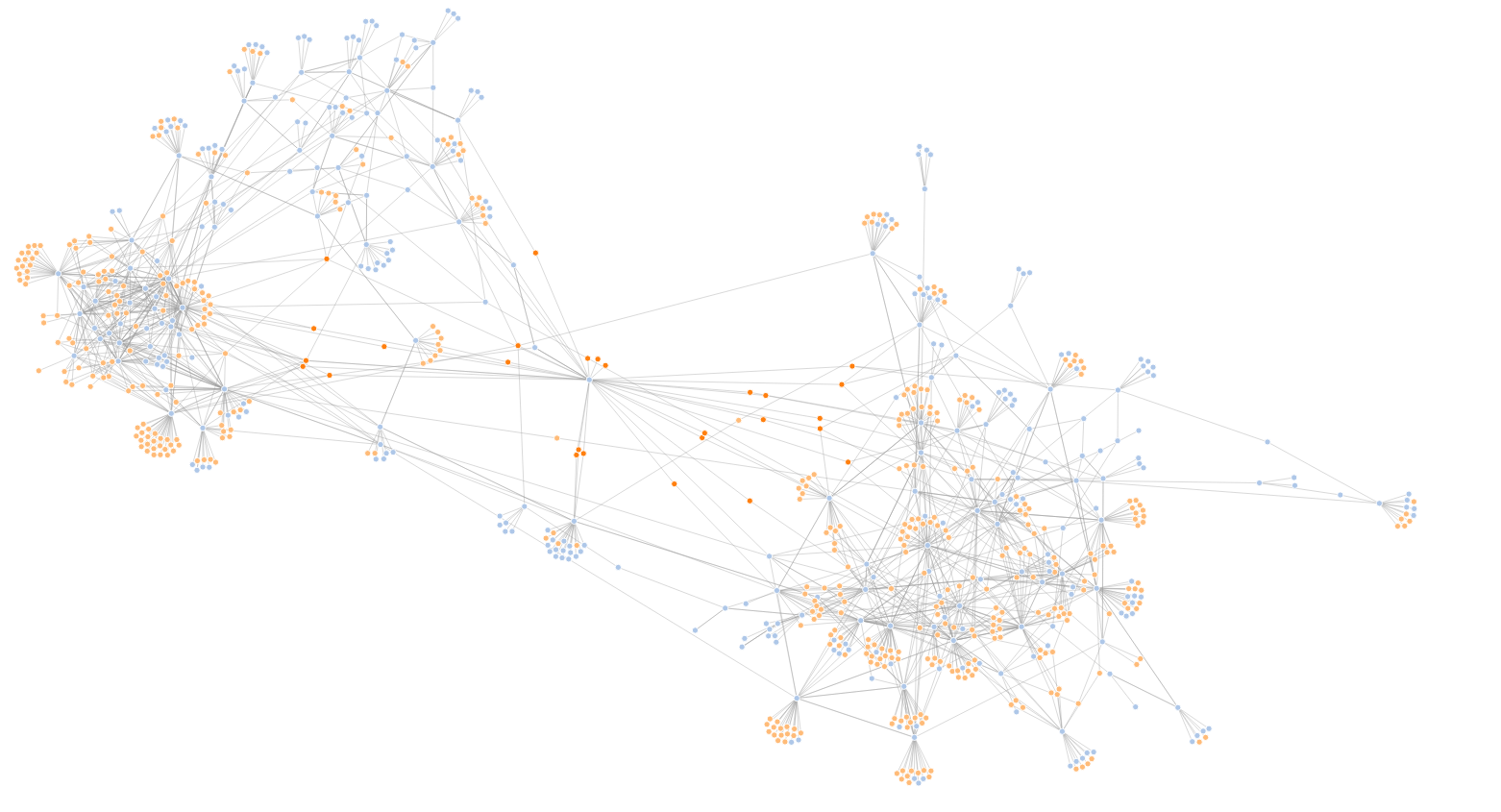
A window into a messy Tag and Category linked website : All the orange dots below are TAGS (WordPress tags)
Log Date: 3/14/2024
Final stage development and testing
The last 4 weeks have been really busy work with tons of testing and coding work.
Here is a sneak pique
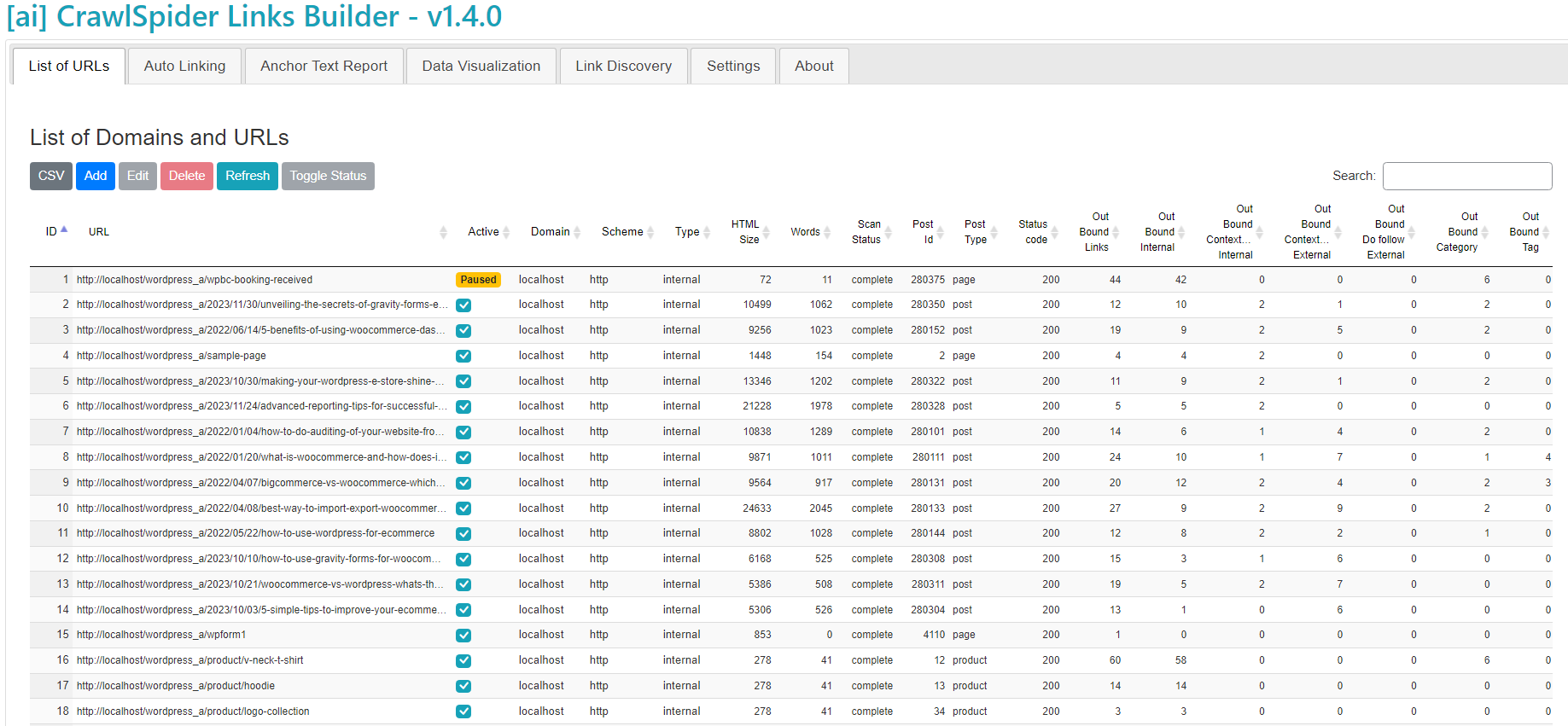
The UI is very SAAS like and does not give any plugin UI vibes.
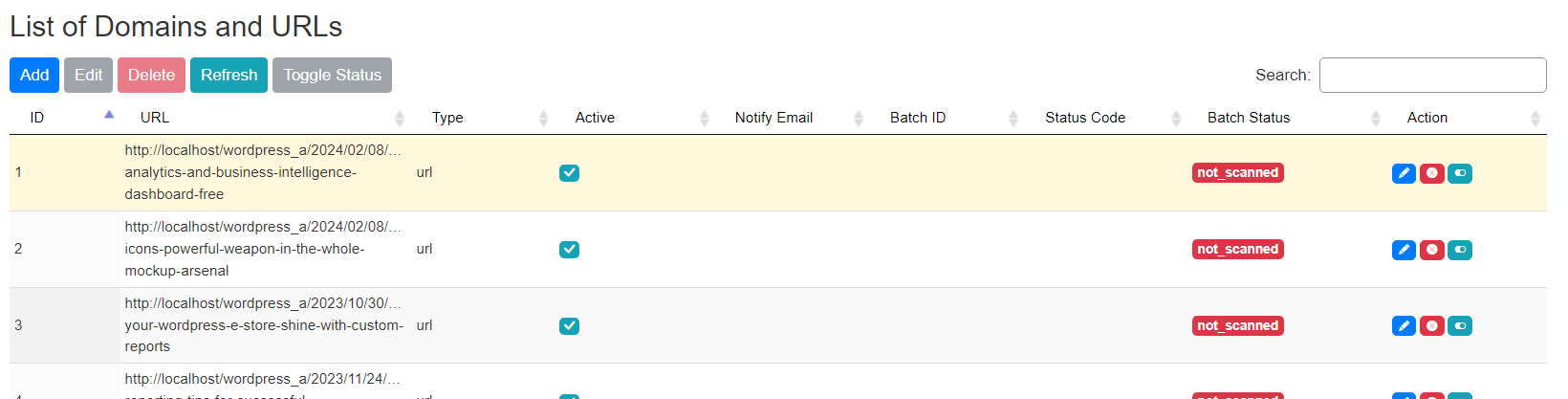
This is the place where you see all the links internal+external including all WordPress post types.
List of metrics
- url_content_length
- absolute_word_cnt
- batch_status
- post_id
- post_type
- last_status_code
- outbound
- outbound_internal
- outbound_contextual_internal
- outbound_contextual_external
- outbound_dofollow_external
- outbound_tag
- outbound_external
- outbound_navigation
- outbound_image
- outbound_category
- inbound
- inbound_internal
- inbound_contextual_internal
- inbound_category
- inbound_tag
- inbound_external
- inbound_navigation
This is one stop source for all your URL Link metrics that tells you how many out going internal links, how many contextual links, inbound links and so on.
The Crawling engine is smart enough to detect and differentiate between Navigation links and Contextual links. Contextual links are the links defined within the core of the body content. If you take the entire HTML page, count all the links and exclude all Navigation links or Sitewide links then what remains is essentially the links in the main body content.
Log Date: 3/20/2024
Link Discovery Process
Signup for the Internal Link Builder Beta/Review Copy